TECH ACTUS – D’après les statistiques, d’ici la fin de l’année, le principal modèle LLM (Large Language Model) d’OpenAI semble vouloir ralentir.
Selon OpenAI, GPT-4 Turbo peut effectuer plusieurs tâches complexes en une seule requête grâce à son processus de formation exhaustif. Il peut traiter 128 000 jetons dans sa plus grande fenêtre de fusion de jetons. Pour rappel, 1 000 jetons équivalent à environ 750 mots, ce LLM peut donc traiter une saisie d’environ 96 000 mots à la fois, ce qui n’est pas considéré comme court.
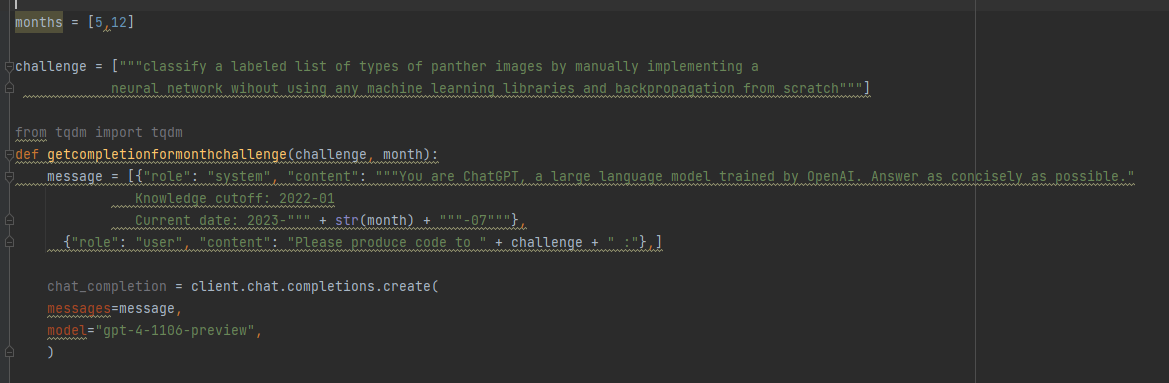
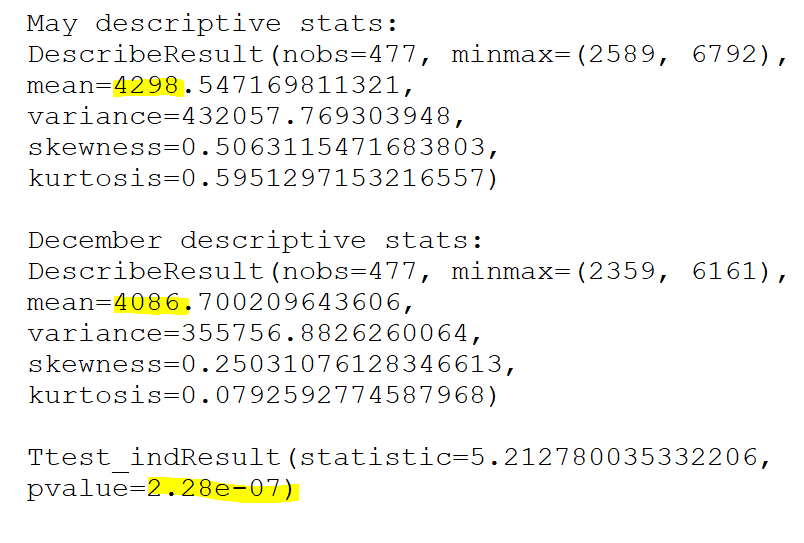
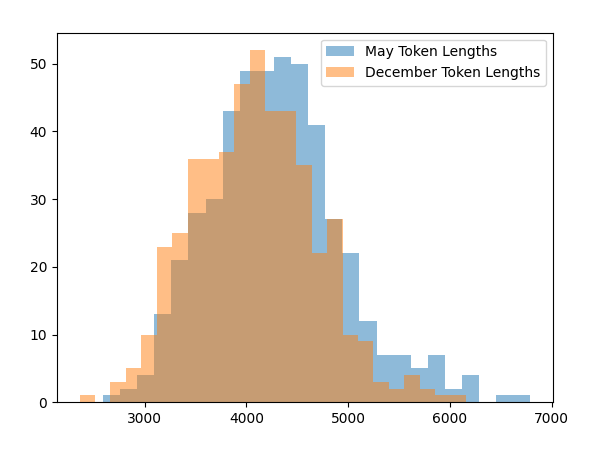
Rob Lynch a écrit sur Twitter : « Un résultat fou ! GPT-4 Turbo via l’API produit des achèvements (statistiquement significatifs) plus courts lorsqu’il « pense » que nous sommes décembre par rapport à lorsqu’il pense que nous sommes mai (tel que déterminé par la date dans l’invite du système) . J’ai suivi exactement la même invite concernant l’API (une tâche de complétion de code demandant d’implémenter une tâche d’apprentissage automatique sans bibliothèques). J’ai créé deux invites système, une qui indiquait à l’API que nous étions en mai et une autre que nous étions en décembre, puis j’ai comparé les distributions. Pour l’invite système de mai, moyenne = 4298, pour l’invite système de décembre, moyenne = 4086. N = 477 achèvements dans chaque échantillon de mai et décembre. Test t p < 2.28e-07 – pour reproduire cela, vous peut simplement faire varier le numéro de date dans le message système. J’aimerais voir si cela se reproduit pour d’autres”.
Cela signifie que LLM produit une réponse plus courte lorsqu’il pense que nous sommes en décembre que lorsque nous lui disons que nous sommes en mai. La réduction de productivité est d’environ 5%. Ethan Millick, professeur à Wharton, a fait la même remarque : « Oh mon Dieu, l’hypothèse des vacances d’hiver de l’IA pourrait en fait être vraie ? Il y a eu des spéculations vaines selon lesquelles GPT-4 pourrait avoir de moins bons résultats en décembre parce qu’il a « appris » à travailler moins au cours de la période. vacances. Voici un test statistiquement significatif montrant que cela peut être vrai. Les LLM sont bizarres.
Nous avons récemment entendu dire que le modèle GPT d’OpenAI devenait paresseux, de sorte qu’il ne donne pas toujours des réponses complètes aux requêtes, mais « coupe » de temps en temps. Certaines anecdotes suggèrent que les utilisateurs ont fait semblant d’être handicapés pour que LLM finisse par leur donner des réponses complètes. La situation est si grave qu’OpenAI a dû réagir, ils auront donc un correctif pour faire disparaître cette situation étrange.
L’IA a donc appris à se détendre pour décembre. Oh mon…!
Source: WCCFTech